
Qwen(通義千問)を本気で評価する — 2026年3月、オープンソースAIの勢力図が変わった
Alibaba発のAIモデル「Qwen」が急速に存在感を増している。ベンチマーク、ローカル実行、API料金、日本語性能、リスクまで、エンジニア視点で徹底検証した。
エンジニアのゆとです。
2026年に入ってから、AI界隈で「Qwen」という名前を見る頻度が明らかに増えた。
Hugging Faceで累計7億ダウンロードを突破し、MetaのLlamaを抜いて最もダウンロードされたモデルファミリーになった。派生モデルは13万以上。2月にはQwen3.5シリーズが立て続けにリリースされ、ベンチマークでClaude 4.5 OpusやGPT-4oに迫るスコアを叩き出している。
「また中国の新しいモデルか」で流してしまうのはもったいない。自分もそう思っていたけど、実際にデータを見てみると、特にコーディングとローカル実行の領域で無視できないレベルに来ている。
この記事では、Qwenの最新モデルラインナップからベンチマーク、実際のローカル実行、API料金、日本語性能、そしてリスクまで、エンジニアが「Qwenを使うべきか」を判断できる材料を全部まとめた。
Qwenとは何か — 30秒で把握する
Qwen(通義千問)は、Alibaba Cloud(阿里雲)が開発しているLLMファミリー。2023年に初代が公開されて以降、急速に進化している。
ポイントを3つだけ押さえておけばいい。
- オープンウェイト: 主要モデルがApache 2.0ライセンスで公開されている。商用利用も可能
- フルスタック: テキスト、コーディング、ビジョン(画像・動画理解)、推論特化モデルまで一通り揃っている
- ローカル実行可能: Ollamaやllama.cppに公式対応。個人のMacやGPUで動かせる
OpenAIやAnthropicがAPIオンリーのクローズドモデルを提供しているのに対して、QwenはMetaのLlamaと同じ「オープンウェイト戦略」を取っている。ただし、最上位のプロプライエタリモデル(Qwen3.5-Plus等)はAPI限定で、ハイブリッド戦略とも言える。
2026年3月時点の最新ラインナップ
Qwen3.5シリーズが2026年2月〜3月にかけて一気にリリースされた。これが現時点の最新世代。
Qwen3.5シリーズ(2026年2月〜3月リリース)
| モデル | 総パラメータ | アクティブパラメータ | アーキテクチャ | リリース日 |
|---|---|---|---|---|
| Qwen3.5-397B-A17B | 397B | 17B | Sparse MoE | 2026/02/16 |
| Qwen3.5-122B-A10B | 122B | 10B | MoE | 2026/02/24 |
| Qwen3.5-35B-A3B | 35B | 3B | MoE | 2026/02/24 |
| Qwen3.5-27B | 27B | 27B | Dense | 2026/02/24 |
| Qwen3.5-9B | 9B | 9B | Dense(マルチモーダル) | 2026/03/02 |
| Qwen3.5-4B | 4B | 4B | Dense(マルチモーダル) | 2026/03/02 |
| Qwen3.5-2B | 2B | 2B | Dense | 2026/03/02 |
| Qwen3.5-0.8B | 0.8B | 0.8B | Dense | 2026/03/02 |
注目すべきはMoE(Mixture of Experts)アーキテクチャの使い方。397Bモデルは総パラメータ397Bだが、推論時に実際に動くのは17Bだけ。つまり、397Bの知識量を持ちながら、推論コストは17Bモデル並みに抑えられる。
さらに驚くべきことに、Qwen3.5-35B-A3B(アクティブ3B)が、旧世代のQwen3-235B-A22B(アクティブ22B)を上回る性能を出している。パラメータ効率の進化速度がすさまじい。
コンテキスト長はネイティブで262,144トークン、最大1,010,000トークンまで拡張可能。対応言語は201言語・方言で、前世代の82から2.5倍に増えた。
他に知っておくべきモデル
- QwQ-32B: 推論特化モデル。OpenAI o1やDeepSeek-R1の対抗馬。32Bパラメータで671BのDeepSeek-R1に迫る数学・推論性能
- Qwen3-Coder-Next: コーディングエージェント特化。80B MoEでアクティブ3B。SWE-bench Verified 70.6%
- Qwen2.5-Coder-32B: コーディング特化モデルとしては現在も広く使われている。HumanEval 88.4%
ベンチマーク — GPT-4o、Claude、Geminiとの直接比較
ここからが本題。Qwenの公式ベンチマーク結果を、GPT-4o・Claude 4.5 Opus・Gemini-3 Proと並べる。
フラッグシップ対決: Qwen3.5-397B-A17B
知識・推論
| ベンチマーク | Qwen3.5-397B | Claude 4.5 Opus | Gemini-3 Pro | GPT-4o |
|---|---|---|---|---|
| MMLU-Pro | 87.8 | 89.5 | 89.8 | 87.4 |
| MMLU-Redux | 94.9 | 95.6 | 95.9 | 95.0 |
| SuperGPQA | 70.4 | 70.6 | 74.0 | 67.9 |
知識・推論ではClaude 4.5 OpusやGemini-3 Proにわずかに届かないが、GPT-4oとはほぼ互角。アクティブパラメータ17Bでこのスコアという点が重要で、推論コストを考えるとコスパは圧倒的。
数学・STEM
| ベンチマーク | Qwen3.5-397B | Claude 4.5 Opus | Gemini-3 Pro | GPT-4o |
|---|---|---|---|---|
| GPQA Diamond | 88.4 | 87.0 | 91.9 | 92.4 |
| AIME26 | 91.3 | 93.3 | 90.6 | 96.7 |
| IMOAnswerBench | 80.9 | 84.0 | 83.3 | 86.3 |
数学はGPT-4oが強い。Qwenは善戦しているが、AIME26やIMOAnswerBenchではClaude・GPT-4oに差をつけられている。
コーディング・エージェント
| ベンチマーク | Qwen3.5-397B | Claude 4.5 Opus | Gemini-3 Pro |
|---|---|---|---|
| SWE-bench Verified | 76.4 | 80.9 | 76.2 |
| LiveCodeBench v6 | 83.6 | 84.8 | 90.7 |
| SWE-bench Multilingual | 69.3 | 77.5 | 65.0 |
SWE-bench Verified(実際のGitHubイシューを修正するベンチマーク)ではClaude 4.5 Opusに4.5ポイント差。コーディングでは依然としてClaudeが一歩リードしている。
ミドルクラス対決: Qwen3.5 Medium vs Claude Sonnet 4.5 vs GPT-5 mini
ここが実は一番面白い。エンジニアが日常的に使うのはフラッグシップより中型モデルだから。
| ベンチマーク | Qwen3.5-122B-A10B | Qwen3.5-27B | GPT-5 mini | Claude Sonnet 4.5 |
|---|---|---|---|---|
| MMLU-Pro | 86.7 | 86.1 | 83.7 | 80.8 |
| SWE-bench Verified | 72.0 | 72.4 | 72.0 | 62.0 |
| BFCL-V4(ツール利用) | 72.2 | 68.5 | 55.5 | 54.8 |
| BrowseComp(検索) | 63.8 | 61.0 | 48.1 | 41.1 |
| Terminal-Bench 2 | 49.4 | 41.6 | 31.9 | 18.7 |
BFCL-V4(ツール利用)でGPT-5 miniを30%上回り、SWE-bench VerifiedではClaude Sonnet 4.5を10ポイント以上上回っている。
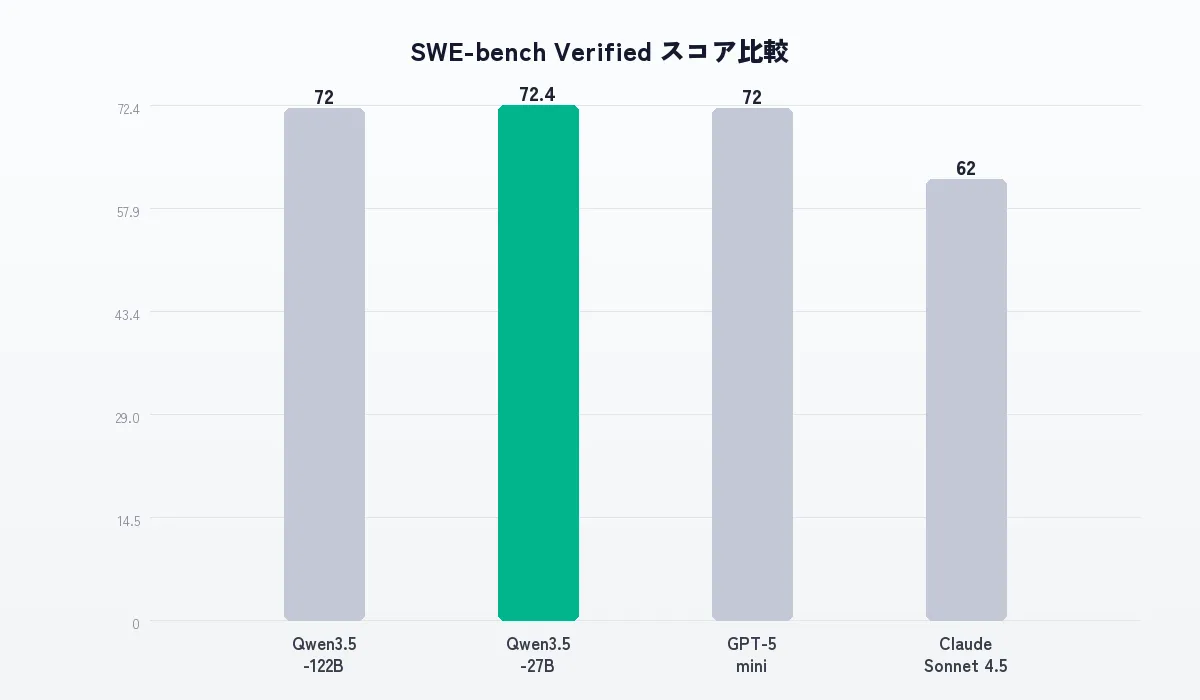
VentureBeatは「Sonnet 4.5の性能をローカルPCで実現」と報じたが、ベンチマークを見る限り、それは誇張ではない。特にエージェント的なツール利用(BFCL-V4)とターミナル操作(Terminal-Bench 2)でのQwenの優位性は明確。
ビジョン(画像・動画理解)
Qwen3.5はネイティブマルチモーダル対応。画像・動画の理解性能も比較する。
| ベンチマーク | Qwen3.5-397B | Claude 4.5 Opus | Gemini-3 Pro |
|---|---|---|---|
| MMMU | 85.0 | 80.7 | 87.2 |
| OCRBench | 93.1 | 85.8 | 90.4 |
| MathVista | 90.3 | 80.0 | 87.9 |
| Video-MME | 87.5 | - | - |
OCRBench 93.1、MathVista 90.3でClaude 4.5 Opusを大幅に上回っている。ドキュメント理解や数式を含む画像の解析ではQwenが明確に強い。請求書の読み取り、技術文書の解析、ホワイトボードの数式認識などのユースケースでは、現時点で最も精度が高いモデルの一つと言える。
コーディング性能の深掘り
エンジニアにとって最も気になるのがここ。Qwenのコーディング特化モデルを掘り下げる。
Qwen2.5-Coder-32B
現時点でローカル実行可能なコーディングモデルとして最も広く使われている。
- HumanEval: 88.4%(GPT-4の87.1%を上回る)
- 40以上のプログラミング言語をサポート
- Aiderベンチマーク(コード修正)でGPT-4oと同等
- Apache 2.0ライセンスで商用利用可能
著名開発者のSimon Willison氏が「自分のM2 Mac(64GB RAM)で動かした中で、コーディング能力が高いと感じた初めてのモデル」と評価している。OllamaでもMLXでも良好に動作するとのこと。
Qwen3-Coder-Next(2026年2月リリース)
最新のコーディングエージェント特化モデル。
- SWE-bench Verified: 70.6%(SWE-Agent使用時)
- SWE-bench Pro: 44.3%(DeepSeek-V3.2の40.9%を上回る)
- 80Bパラメータ中、1トークンあたり3Bしか活性化しない超スパースMoE
3Bアクティブで10〜20倍大きいモデルに匹敵する性能。ただし、llama.cppでの最適化がまだ追いついておらず、期待値35〜60 tok/sに対して7.7 tok/sしか出ないという報告もある(GitHub Issue #19480)。本番投入にはもう少し時間がかかりそう。
Qwen Code(CLIコーディングエージェント)
Claude CodeやCursorに対抗するターミナルベースのAIコーディングエージェントも公開されている。GitHub Stars 19.7K。ターミナルからコード生成・編集・デバッグを指示できる。
ローカル実行ガイド — 自分のマシンで動かす
Qwenの最大の魅力はオープンウェイトであること。つまり、自分のマシンで動かせる。データを外部に送信する必要がない。
必要スペック目安
| モデル | Q4量子化 VRAM | 推奨環境 |
|---|---|---|
| Qwen3.5-0.8B | ~1GB | ほぼ何でも動く |
| Qwen2.5-Coder-7B | ~4-5GB | RTX 3060 12GB / M1 Mac 16GB |
| Qwen3.5-27B | ~16GB | RTX 4090 24GB / M4 Pro 48GB |
| Qwen2.5-Coder-32B | ~20GB | RTX 4090 / Mac M2 64GB |
| Qwen3.5-35B-A3B | ~20GB | 同上(ただしアクティブ3Bなので推論は軽い) |
Ollamaでの実行手順
最も簡単な方法はOllama。3コマンドで動く。
# Ollamaインストール(Mac/Linux)
curl -fsSL https://ollama.com/install.sh | sh
# Qwen2.5-Coder 7Bを実行(8GB VRAM以上)
ollama run qwen2.5-coder:7b
# 32Bバージョン(24GB VRAM以上)
ollama run qwen2.5-coder:32b
# 最新のQwen3.5 27B
ollama run qwen3.5:27b量子化済みモデル(Q4_K_M、Q5_K_M等)がOllama公式で提供されているので、FP16で動かす必要はない。7Bモデルなら8GBのVRAMで実用的な速度で動く。
推論速度の参考値
- 8Bモデル: 約95 tok/s(RTX 4090)
- 32Bモデル: 約34 tok/s(RTX 4090)
- 7Bモデル on M1 Mac 16GB: 十分実用的な速度(具体値は環境依存)
他のフレームワーク: vLLM、SGLang、LM Studio、Jan.aiでも動作する。
API料金比較 — 圧倒的なコスト差
ローカル実行が難しい場合はAPIで使える。ここが衝撃的に安い。
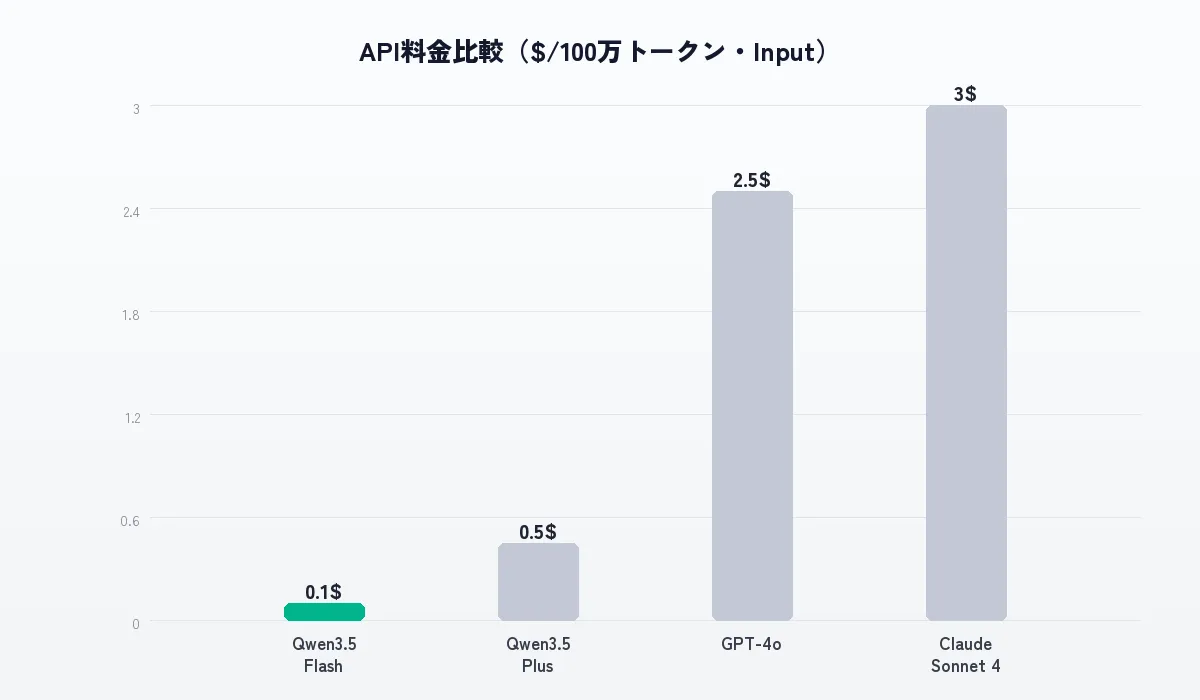
主要モデルのAPI料金(100万トークンあたり、USD)
| モデル | Input | Output |
|---|---|---|
| Qwen3.5-Plus | $0.40〜$0.50 | $2.40〜$3.00 |
| Qwen3.5-Flash | $0.10 | $0.40 |
| Qwen-Max | $1.20〜$3.00 | $6.00〜$15.00 |
| Claude Sonnet 4(参考) | $3.00 | $15.00 |
| GPT-4o(参考) | $2.50 | $10.00 |
Qwen3.5-Flashは入力$0.10/100万トークン。Claude Sonnetの1/30、GPT-4oの1/25。バッチ処理ならさらに50%割引。
OpenAI互換APIフォーマットに対応しているので、既存のOpenAI SDKを使ったコードをほぼそのまま流用できる。エンドポイントとAPIキーを変えるだけ。
レートリミットも緩い。Qwen3.5-Plusは15,000 RPM(リクエスト/分)、5,000,000 TPM(トークン/分)。GPT-4oの標準的なレートリミットと比べて大幅に余裕がある。
日本語性能 — 実用レベルに到達しているか
海外モデルの日本語性能は常に気になるポイント。
Qwen3の日本語ベンチマーク(Shisa.AI評価)
| モデル | ELYZA 100 | JA-MT | Rakuda | Tengu | 平均 |
|---|---|---|---|---|---|
| Qwen3-30B-A3B | 8.52 | 8.67 | 8.85 | 7.42 | 8.36 |
| Qwen3-8B | 8.08 | 8.48 | 7.80 | 6.86 | 7.81 |
| Qwen2.5-7B(参考) | - | - | - | - | 6.78 |
10点満点でQwen3-30B-A3Bが平均8.36。70Bクラスの日本語特化モデル(Shisa V2: 8.39)にほぼ匹敵するスコアを、わずか3Bアクティブで出している。
Qwen2.5-7Bの6.78からQwen3-8Bの7.81への改善も大きい。世代が進むごとに日本語性能は確実に上がっている。
日本語特化派生モデル
- Qwen3-Swallow(東京科学大学 + 産総研): 8B/32Bモデルが同規模以下のオープンLLMで日本語最高性能(2026年2月時点)
素のQwen3でも日本語は実用レベル。日本語特化が必要ならQwen3-Swallowを選べばいい。選択肢があるのはオープンウェイトの強み。
Qwenの弱点とリスク — ここは正直に書く
ベンチマークだけ見ると最強級だが、実用上の課題は明確にある。
- ハルシネーション(幻覚)が多い
独立テスト機関PointGuard AIの評価で、Qwen2.5は57.6%の失敗率を記録している。偽のURL、存在しないソースを生成する傾向がある。
ベンチマークスコアと実際の信頼性は別物。Claude やGPT-4oと比べて「当たり外れ」が大きいという評価が、Reddit・Hacker News・Trustpilotで繰り返し指摘されている。
エンタープライズのプロダクションでそのまま使うにはまだリスクがある。
- 検閲とバイアス
中国政府の方針に沿った回答制限がかかる場面がある。研究者の調査で、Qwenの内部指令に「中国に関する回答はポジティブかつ建設的に」という内容が含まれていることが確認されている。
ただし、オープンウェイト版(ローカル実行)ではこの検閲はほぼ機能しないというテスト結果もある。API版(特に中国国内向け)とローカル版で挙動が異なる点は把握しておくべき。
- データプライバシーの懸念
API経由で使う場合、データは中国のサーバーに送信される。EU GDPRに必要な域内代表者をQwenは設置していない。
プロプライエタリなコードや機密情報を扱う場合は、ローカル実行一択。これはQwenに限らず、どのクラウドAIサービスでも同じ判断基準だが、中国企業であることへの追加の懸念は現実問題として存在する。
- llama.cppの最適化が追いついていない
最新のMoEモデル(特にQwen3-Coder-Next)では、llama.cppでの推論速度が期待値の1/5程度にとどまるケースがある。新アーキテクチャへの最適化は時間がかかる。安定して使いたいなら、Qwen2.5-Coderシリーズがまだ無難。
今すぐQwenを試す3つの方法
方法1: ブラウザで即座に試す(セットアップ不要)
https://chat.qwen.ai/ にアクセスするだけ。アカウント作成なしでも基本的な会話ができる。モデル選択でQwen3-Coderなどを指定可能。
まずここで日本語の応答品質やコーディング能力を確認するのが手っ取り早い。
方法2: Ollamaでローカル実行(推奨)
curl -fsSL https://ollama.com/install.sh | sh
ollama run qwen2.5-coder:7b2コマンドで完了。データが外部に出ないので、業務コードの補助にも安心して使える。
方法3: APIで使う
Alibaba Cloud Model Studio(https://modelstudio.alibabacloud.com/)でAPIキーを取得。OpenAI互換フォーマットなので、既存コードのエンドポイントとキーを差し替えるだけで動く。
エンジニアとしてのQwenへの評価
ここからは自分の意見。
Qwenは「ローカルで動くAI」として現時点で最良の選択肢の一つになった。
正直、半年前まではLlamaの天下だった。でもQwen3.5-35B-A3Bが3Bアクティブで旧世代235Bを超えた時点で、パラメータ効率の競争はQwenが一歩先に出た。Qwen2.5-Coder-32BをOllamaで動かしてコーディング補助に使う体験は、クラウドAPIに課金しなくてもここまでできるのかと思えるレベルに達している。
一方で、「ベンチマーク番長」の域を出ていない部分もある。ハルシネーション率57.6%は看過できない数字で、ChatGPTやClaudeのように「雑に聞いても大体正しい答えが返ってくる」という信頼感はまだない。ベンチマークの数字と日常的な使用感の間にギャップがある。
使い分けとしては:
- ローカルでのコーディング補助 → Qwen2.5-Coder-32B(Ollama)が最適解。データ外部送信なし、無料、実用的な品質
- プロダクションのAPI → まだClaude/GPT-4oの方が安定。Qwen APIは「安いけど当たり外れ」のリスクを許容できる場面で
- ビジョン(画像理解) → OCRやドキュメント解析ならQwenが最強。この用途に限ればClaudeより上
- エージェント的なツール利用 → ベンチマーク上はQwenが圧倒的に強い。ただし実運用での安定性は要検証
Qwenの最大の価値は、「プロプライエタリモデルに匹敵する性能が、Apache 2.0ライセンスで手元で動く」こと。中国企業だからというだけで選択肢から外すのはもったいない。ローカル実行ならデータの懸念もない。
ただし、ハルシネーションの多さは事実なので、Qwenの出力は必ず自分で検証する前提で使うべき。盲信は禁物。そこさえ押さえておけば、コスト面でもプライバシー面でも、エンジニアのツールボックスに入れておく価値は十分にある。
この記事の情報は2026年3月時点のものです。AI分野は変化が速いため、最新情報は各公式サイトで確認してください。
関連記事
- CRMのAI機能を本気で比較した — 5ツール横比較 — 予測AI・生成AI・AIエージェントの3軸で徹底比較
- エンジニア目線で選ぶCRM — API・カスタマイズ・開発者体験比較 — API仕様・レートリミット・コード拡張性の技術検証



