万能AI 1体 vs 専門家AIチーム——研究データと実践事例で徹底比較
Claude Codeを1体で使うか専門家チームに分けるか。Anthropic・Google・スタンフォードの研究データ、CyberAgent・Goldman Sachsの実践事例、CrewAI・LangGraphのフレームワーク比較まで。マルチエージェントAIの「本当のところ」を定量データで解説。
エンジニアのゆとです。
この記事は、noteに書いた「Claude Codeを『一人の万能AI』として扱うのと『専門家AIチーム』に育てるの、どっちが正解なんだろうか」の詳細版。noteでは体験と要点を中心にまとめたけど、調べていく中で出てきた研究データ、事例、フレームワーク比較が想像以上に面白かったので、こっちで全部まとめることにした。
noteの方は体験ベースの読み物として、こっちはデータと事例のリファレンスとして使ってもらえたら。
この記事でわかること
- 万能AIが「70点止まり」になる技術的理由(Anthropic・Stanford・Google Researchの研究)
- マルチエージェントで実際どれくらい性能が上がるか(定量ベンチマーク5本)
- コストとエラーのリアルなトレードオフ(最大6倍のトークンコスト、17倍のエラー増幅)
- 世界の企業・個人の実践事例(成功も失敗も)
- 主要フレームワークの比較(CrewAI / LangGraph / Agents SDK / Claude Code)
- 市場予測と今後の方向性
なぜ「万能AI」は70点止まりになるのか

コンテキストウィンドウの汚染
Anthropicのエンジニアリングブログで詳しく解説されている、最も根本的な問題。

LLMの中で動いているTransformerのアテンション機構は、入力トークン数の二乗に比例して計算量が増える。
- 10Kトークン → 1億アテンションペア
- 100Kトークン → 100億アテンションペア
- 1Mトークン → 1兆アテンションペア
トークン数が10倍になるごとに、1トークンあたりのアテンション重みが10倍に希釈される。
典型的な20,000トークンのセッションで、実際にタスクに関連する情報はわずか約500トークン。信号対雑音比たった2.5%。残りの97.5%は「ノイズ」としてAIの処理能力を食っている。
さらにエージェントは最初のターンの60%以上をコンテキスト内の情報検索に費やしていて、本来やるべき推論やコーディングに使えていないというデータもある。
専門エージェントに分けると、各AIがクリーンなコンテキストウィンドウで動作する。数万トークンを使って探索しても、リードエージェントには1,000〜2,000トークンの要約だけを返す。
Lost-in-the-Middle問題
スタンフォード大学が2023年に発見し、2024年にTACLで正式に発表された研究。
長いコンテキストの中で:
- 先頭に関連情報がある → 高精度
- 末尾に関連情報がある → 高精度
- 中間に関連情報がある → 30%以上の精度低下
U字型のカーブを描く。最悪のケースでは、情報を一切与えないベースラインよりも精度が下がることすらあった。
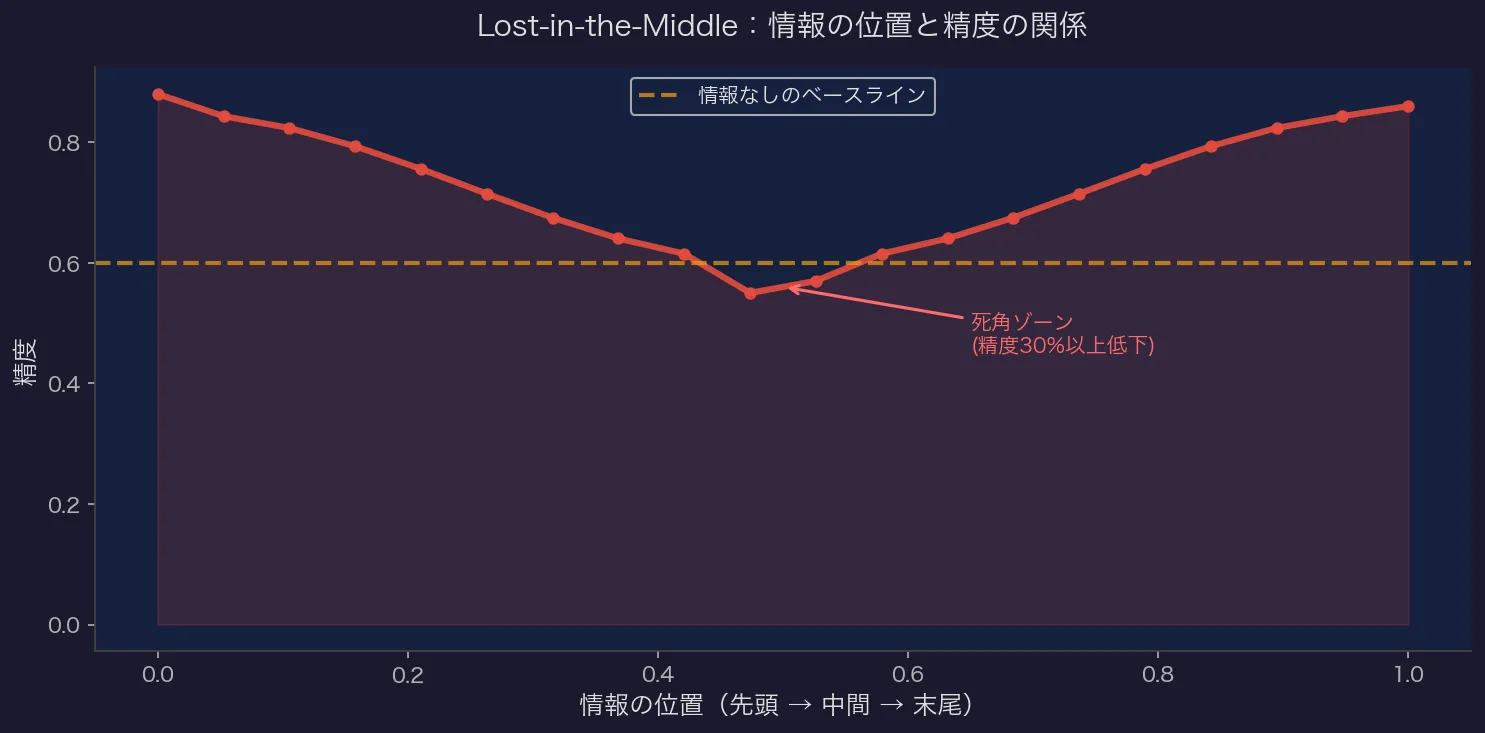
万能AIに大量の指示や知識を詰め込むと、重要な情報がこの「死角」に入るリスクが高まる。専門エージェントは各自のコンテキストが短いため、この問題を構造的に回避できる。
システムプロンプトの収穫逓減

プロンプトエンジニアリングには明確な限界がある。
- 最初の5時間 → 35%の改善
- 次の20時間 → 5%
- さらに40時間 → 1%
指数関数的に効果が減衰する。
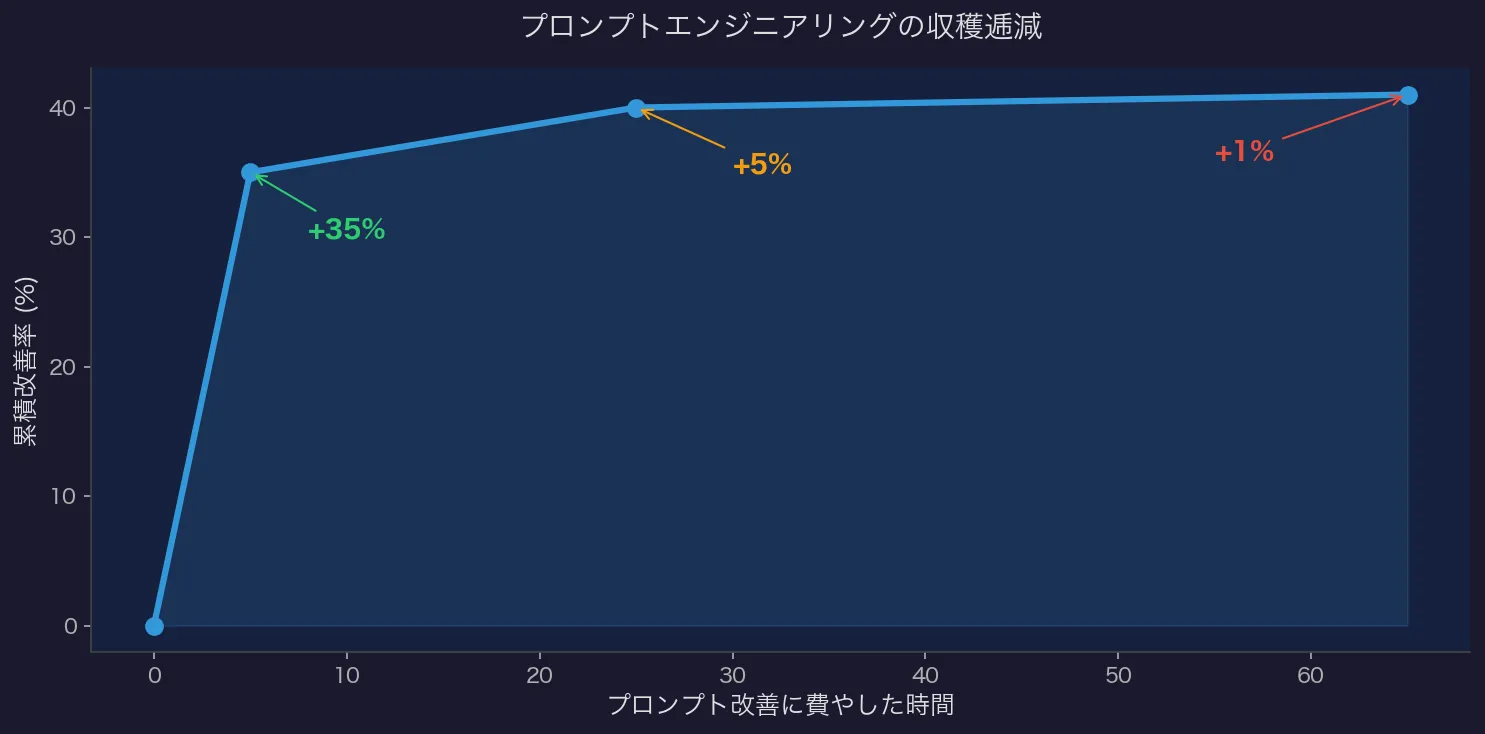
事例として、ある法律文書分析で1つの巨大プロンプトを4つの専門エージェントに分割しただけで、各プロンプトの長さが1/4になり、信頼性が2倍に向上した。プロンプトを磨くより構造を変えた方が早かった。

実務的な目安として「85%精度閾値ルール」がある。適切なプロンプト構成で精度85%を下回る場合、問題はプロンプトではなくアーキテクチャにある。
35分の壁

全エージェントの成功率が35分を超えると低下し始め、タスク時間を2倍にすると失敗率は4倍に。
全18モデル(GPT-4.1、Claude Opus 4、Gemini 2.5 Pro含む)で「長くなるほど劣化」を確認。マルチエージェントは長期タスクを並列の短期タスクに分解することでこの劣化を回避するが、分解できないタスクには無力。
定量ベンチマーク:専門チームは実際どれくらい強いのか
Anthropicマルチエージェント・リサーチシステム

Claude Opus 4をリードエージェント、Claude Sonnet 4をサブエージェントとしたマルチエージェント構成の結果:
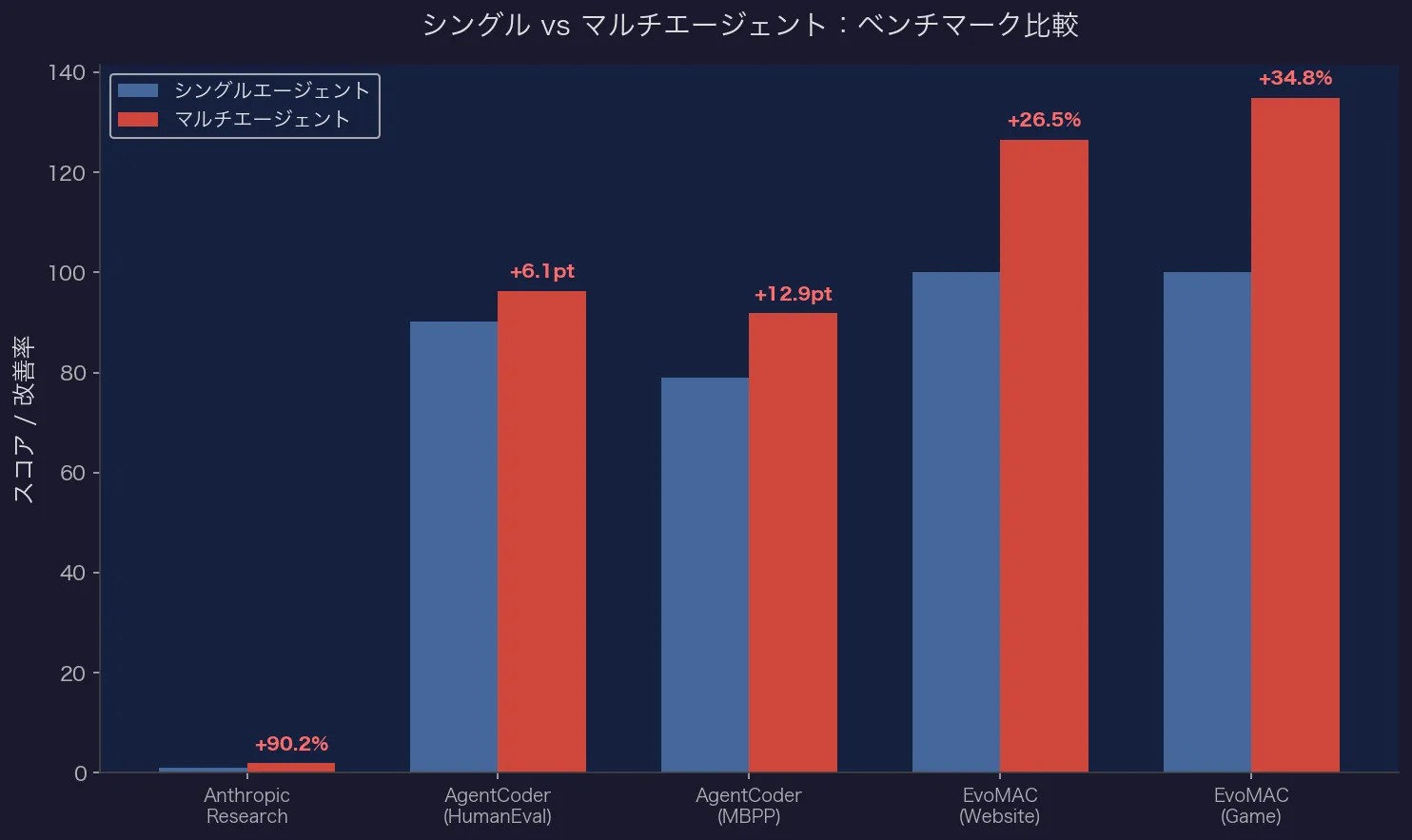
- 単一エージェントのClaude Opus 4を90.2%上回った
- 複雑なクエリの調査時間を最大90%短縮
- ただしトークン消費は15倍
- パフォーマンス差の80%はトークン使用量で説明できる
最後の点は重要。「同じ予算をシングルエージェントに投下しても同等の結果が得られる可能性」が示唆されている。つまり性能差の正体は「頭の数」ではなく「投入リソースの総量」かもしれない。
Mixture-of-Agents(MoA)
複数のLLMを階層構造で組み合わせるアプローチ。
| ベンチマーク | MoA | GPT-4 Omni | 差分 |
|---|---|---|---|
| AlpacaEval 2.0 | 65.1% | 57.5% | +7.6pt |
| MT-Bench | 9.40 | 9.19 | +0.21 |
アーキテクチャは3層×6エージェント(Qwen1.5-110B、LLaMA-3-70B、Mixtral-8x22B等)。オープンソースモデルのみでGPT-4oを超えた初めての事例。
ただし2025年の後続研究(Self-MoA)で、同一モデルの複数出力を集約するだけでMoAを6.6%上回るという結果も。モデル間の多様性よりモデル内の多様性が有効な場合がある。
AgentCoder
3つの専門エージェント(プログラマ、テスト設計者、テスト実行者)に分離した場合の結果:
| ベンチマーク | AgentCoder | 従来SOTA | 改善幅 |
|---|---|---|---|
| HumanEval | 96.3% | 90.2% | +6.1pt |
| MBPP | 91.8% | 78.9% | +12.9pt |
- ゼロショットGPT-4比で平均32.7%改善
- Claude-instant-1ベースでは42.8%改善
- トークンオーバーヘッドは従来手法の約半分(56.9K vs 138.2K)
「分けた方が安くて強い」の理想形。
EvoMAC(ICLR 2025)
ソフトウェア開発タスクでの専門エージェント協働:
- Website Basic: 既存SOTAを**+26.5%**上回る
- Game Basic: **+34.8%**上回る
- HumanEval: **+6.1%**上回る
- 既存のマルチエージェント手法と比較しても20%以上の改善
エージェントシステムスケーリング研究(Google Research, 2025年12月)

タスク種別ごとの包括的比較。マルチエージェントが常に優れているわけではないことを示した重要な研究。
| タスク | 最良のMAS変種 | シングル比 |
|---|---|---|
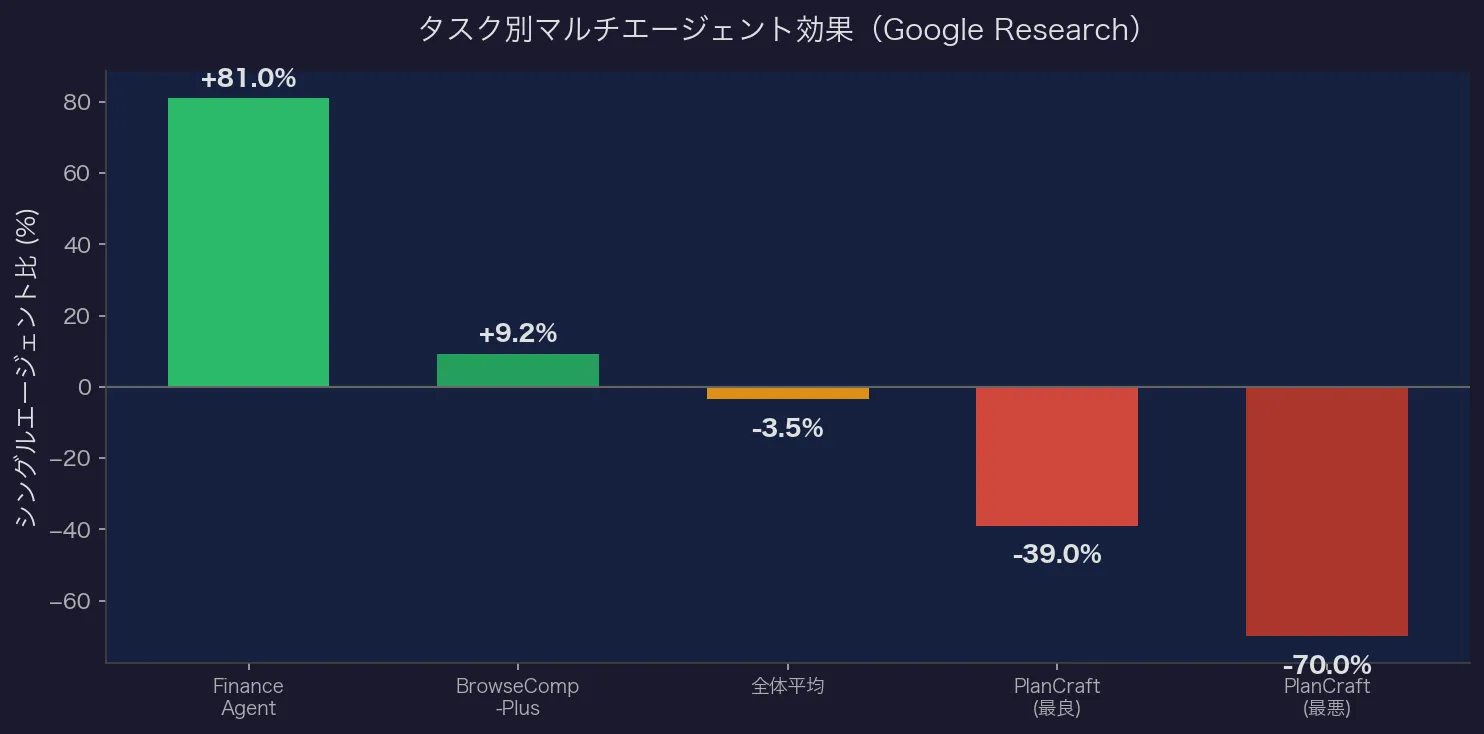
| Finance Agent | 集中型協調 | +57%〜+81% |
| BrowseComp-Plus | 分散型協調 | +9.2% |
| PlanCraft | 全MAS変種 | -39%〜-70%(悪化) |
全体平均は-3.5%で、標準偏差45.2%。つまりタスクによって結果が大きく異なる。
重要な発見:シングルエージェントの精度が約45%を超えるとマルチエージェントのリターンが減少・マイナスに転じる。
トレードオフ:コストとリスクの実測値

トークンコスト
同じスケーリング研究(arXiv 2512.08296)の実測値:
| アーキテクチャ | トークンオーバーヘッド | シングル比 |
|---|---|---|
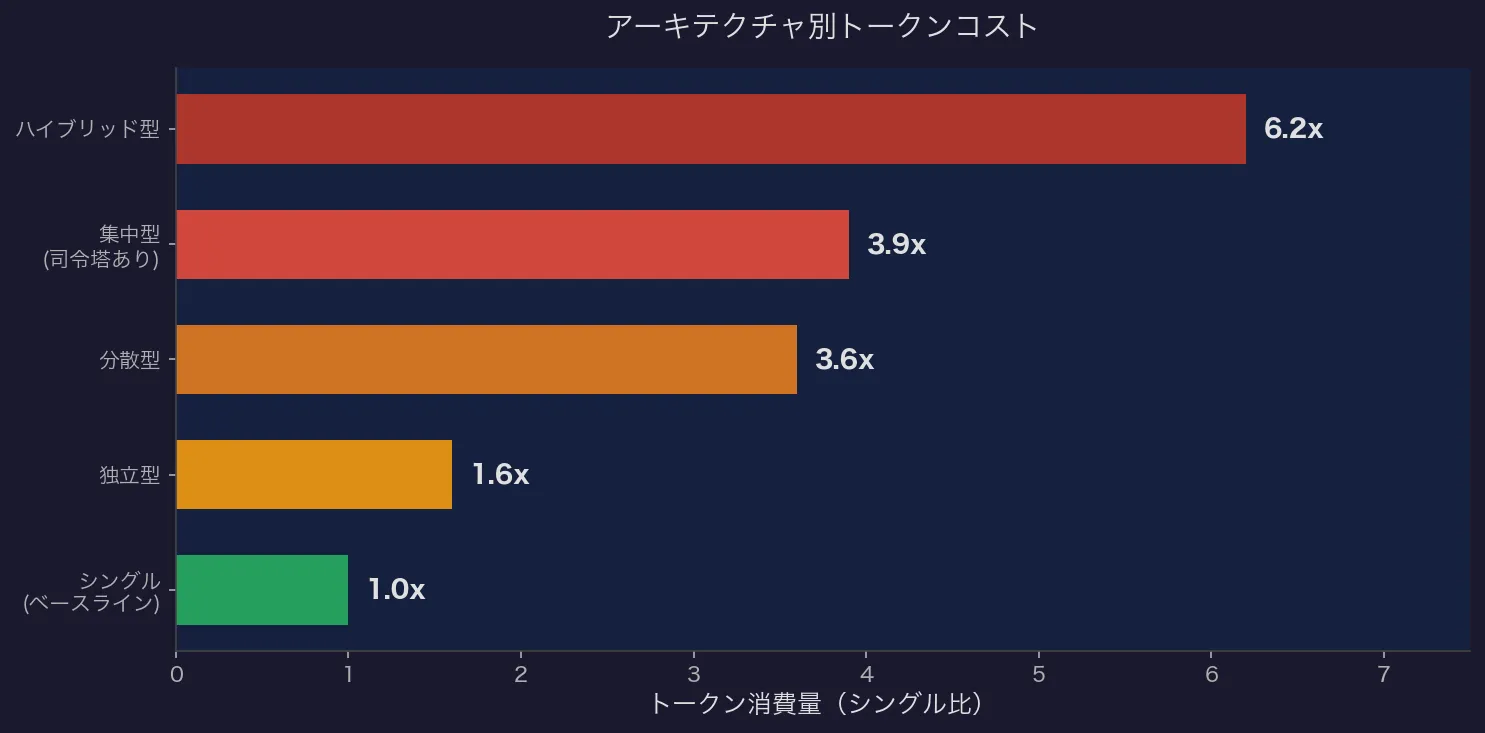
| 独立型 | +58% | 1.6倍 |
| 集中型 | +285% | 3.9倍 |
| 分散型 | +263% | 3.6倍 |
| ハイブリッド型 | +515% | 6.2倍 |
推論ターン数もべき乗則で増加(指数1.724):シングル7.2ターン → ハイブリッド44.3ターン。
エラー増幅

1,642実行トレースの分析結果:
| アーキテクチャ | エラー増幅率 |
|---|---|
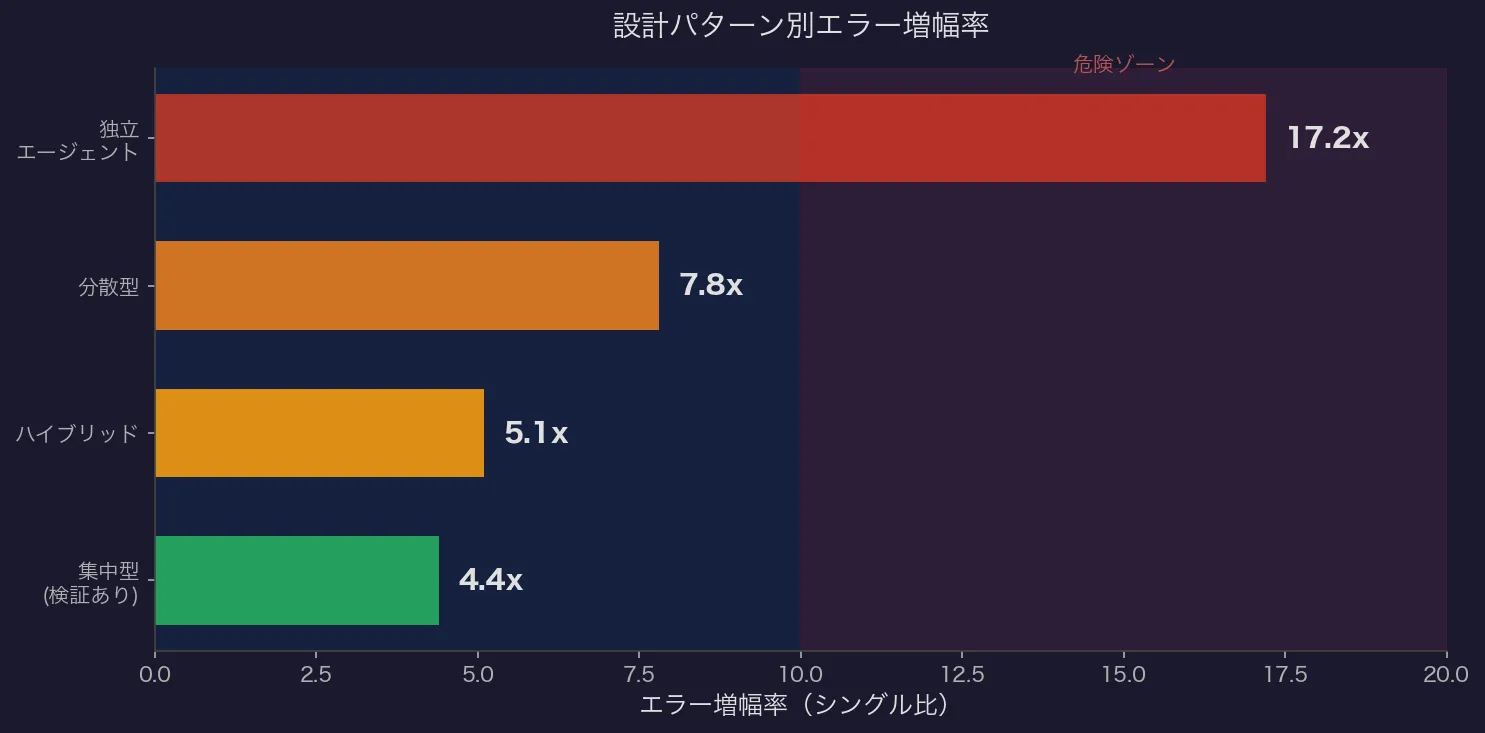
| 独立エージェント | 17.2倍 |
| 分散型 | 7.8倍 |
| ハイブリッド | 5.1倍 |
| 集中型(検証あり) | 4.4倍 |
失敗率は41%〜86.7%。主な原因はコーディネーション障害(36.9%)——JSON形式の不一致やフィールド名の変動。
「エージェントを雑に並べただけ」の状態は極めて危険。司令塔+バリデーションの設計で大幅に抑制できる。
マルチエージェント・ディベートの限界
注意すべき研究結果として、ICLR 2025 / ICML 2024のマルチエージェント・ディベート(MAD)研究がある。
- GPT-4o-miniでの比較: Self-Consistency 82.13% vs MAD 74.73%(MADが劣る)
- HumanEval: CoT 78.05% vs MAD 68.09%(MADが劣る)
- ディベートラウンドやエージェント数を増やしても安定的な改善なし
結論として「ディベート形式のMADは、self-consistencyやアンサンブルなどのシンプルな手法を安定的に上回ることはない」。エコーチェンバー効果のリスクも指摘されている。
世界の実践事例
企業事例
CyberAgent(日本)——6人→2人でアウトプット維持

6人の開発チームを2人に縮小し、37個のSkill + 24個のSubAgentで運用。SubAgentは言語別実装者(gopher、nextjs-implementer、react-implementer等)、レビュー担当(code-tech-reviewer、code-spec-reviewer、code-simplifier)、インフラ(aws-sre、snowflake-sre)に分化。
4フェーズの自動パイプライン(要件定義→技術設計→実装→CI/CDレビュー)を構築。要件定義が数時間→10-20分に短縮。人間は同時に3-4タスクを監督(git worktreeで並列管理)。PRは80点以上で自動承認。
課題:暗黙知がドキュメント化されていない部分でAIが失敗する。10以上の並列PRを2人でレビューするのは認知的限界がある。
博報堂——AIにブレストさせる

「企画AI」「製造AI」「物流AI」「リテール営業AI」等の専門知識を持つ複数AIが自律議論するサービスを2024年3月から業務活用。「Nomatica」として外販もしている。
Goldman Sachs——AIエンジニアを数百台並列投入

Cognition社のDevinを12,000人の人間開発者と並行して数百台展開。将来は数千台に拡大予定。
- セキュリティ脆弱性修正: 人間30分→Devin 1.5分(20倍)
- PRマージ率: 34%→67%に倍増
Nubank(ブラジル)——レガシーコード移行
8年もののETLモノリス(数百万行)のサブモジュール分割。12倍の工数削減、20倍以上のコスト削減。月単位→週単位で完了。
PwC——コード生成精度10%→70%
CrewAIのマルチエージェントでコンサルタント向け独自言語のコード生成精度を10%→70%に改善。
Thoughtful AI(ヘルスケア)——6体の専門AI
医療事務に6体の専門AIを配置(EVA:保険適格性確認、PAULA:事前承認、CODY:コーディングレビュー、CAM:請求処理、DAN:否認管理、PHIL:支払い記帳)。
- 適格性確認を11倍頻繁に実施
- 承認関連否認80%削減
- コーディングエラー98%削減
- 手動作業95%削減
個人事例
HAMYの9並列コードレビュー
Test Runner / Linter / Code Reviewer / Security Reviewer / Quality Reviewer / Test Quality Reviewer / Performance Reviewer / Dependency Reviewer / Simplification Reviewerの9体が並列実行。Claude Codeの.claude/commandsにスキルとして配置。AI提案の有用率が50%未満→約75%に改善。
bredmond1019の10+ Claude並列オーケストレーション

Meta-Agent(コードは書かず他エージェントを管理)+ Redis Task Queue + 専門Worker Agent(frontend、backend、testing、docs、refactoring)。12,000行以上のフロントエンドリファクタで手動2日→並列2時間。コンフリクト0件。
Artem Zhutovの「cmux」
10体のClaude Codeエージェントを1つのターミナルから管理する自作ツール。名前付きワークスペース + オーケストレーターパターン + 3コマンド(list / read / send)。30分ごとの自動進捗チェック、3時間ごとの「内省割り込み」で自動化疲れを防ぐ設計。
失敗事例
Klarna——華々しく発表して撤回
OpenAIと組んで700人の人間を削減。AI1体が月230万件を処理、4,000万ドルのコスト削減を発表。しかし複雑な問い合わせでAIが行き詰まり、顧客満足度が低下。
CEOの発言:「効率とコストに集中しすぎた。その結果、品質が低下した。これは持続可能ではない」
現在は人間のサポートスタッフを再雇用し、AI+人間のハイブリッドに転換。
Gartner予測——40%が中止
2027年末までにアジェンティックAIプロジェクトの40%以上が中止される予測。理由はコスト膨張、不明確なROI、リスク管理の不備。「エージェントウォッシング」も横行しており、数千のベンダーのうち正当な技術を持つのは約130社のみ。
フレームワーク比較(2026年時点)
マルチエージェントを実現するための主要フレームワーク。
CrewAI
ロールベースモデル。現実の組織構造を模倣し、エージェントに「役割」を割り当てる。
- 資金調達: 1,800万ドル(Insight Partners主導)。Andrew Ng、Dharmesh Shahがエンジェル投資
- 採用: Fortune 500の60%が利用。月間1,000万以上のエージェント実行。150カ国以上
- 特徴: 最も直感的で立ち上げが速い。ビジネスワークフロー自動化に最適
- 弱点: トークン消費量が最も多い
LangGraph
グラフベースのワークフロー。有向グラフで状態管理・エラーリカバリ・並列処理を実現。
- 採用: Klarna、Replit、Elastic、LinkedInなどが本番利用。2025年末にv1.0
- 特徴: 最大の制御性。チェックポイント永続化・障害復旧・Human-in-the-loop対応
- 強み: トークン効率が最も高い。エンタープライズ向き
OpenAI Agents SDK(旧Swarm)
教育用フレームワークだったSwarmが2025年にAgents SDKとして本番対応に進化。
- 機能: トレーシング、ガードレール、セッション管理、入出力バリデーション
- Codex: 複数エージェントの並列実行が可能。カスタムエージェントはTOMLファイルで定義
- 注目: Assistants APIは2026年半ばにサンセット予定。MCPベースのアーキテクチャへ移行を推進
Anthropic(Claude Code)
サブエージェント、Agent Teams、MCPの三本柱。
- サブエージェント:
.claude/agents/にMarkdown+YAMLフロントマターで定義。タスクがマッチすると自動委譲 - Agent Teams: Opus 4.6と同時に正式発表。チームリード + 独立コンテキストウィンドウのチームメイト + 共有タスクリスト + P2Pメッセージング
- 公式メッセージ: 一貫して「シンプルなパターンから始め、必要な時だけマルチエージェントに」

AutoGen / Microsoft Agent Framework
2024年末に分裂。元開発者Chi Wang、Qingyun Wuがマイクロソフトを離れ、コミュニティ主導のフォーク「AG2」を設立。Microsoft側はAutoGen 0.4でアクターモデルベースに完全刷新し、Semantic Kernelと統合して「Microsoft Agent Framework」としてパブリックプレビュー中。
Google A2A / MCP
異なるプロバイダー・フレームワーク間のエージェント相互運用性の標準化。
- A2A: HTTP、SSE、JSON-RPCベース。150以上の組織がサポート。2025年12月にLinux Foundation傘下に
- MCP: Anthropicが2024年11月に発表。サーバーDL数が10万→800万超。5,800以上のMCPサーバー、300以上のクライアント
市場予測と数字
期待の大きさ
- エージェンティックAI市場: 2026年に約100億ドル → 2034年に1,990億ドル予測(CAGR 42%超)
- McKinsey: AIエージェントが年間2.6〜4.4兆ドルの価値を創出する可能性
- McKinsey自社: 社員40,000人に対してAIエージェント25,000体を運用中。年末までに同数に
- PwC調査: 米国経営幹部の79%がAIエージェントを本番運用中
- Gartner: 2026年末までにエンタープライズアプリの40%がタスク特化型AIエージェントを搭載(2025年は5%未満)
現実の冷水
- 完全自律型AIエージェントへの経営幹部の信頼: 2024年の43% → 2025年には22%に急落
- アクション精度85%でも10ステップのワークフローの成功率はわずか20%(0.85^10)
- 2027年末までにプロジェクトの40%超が中止予測
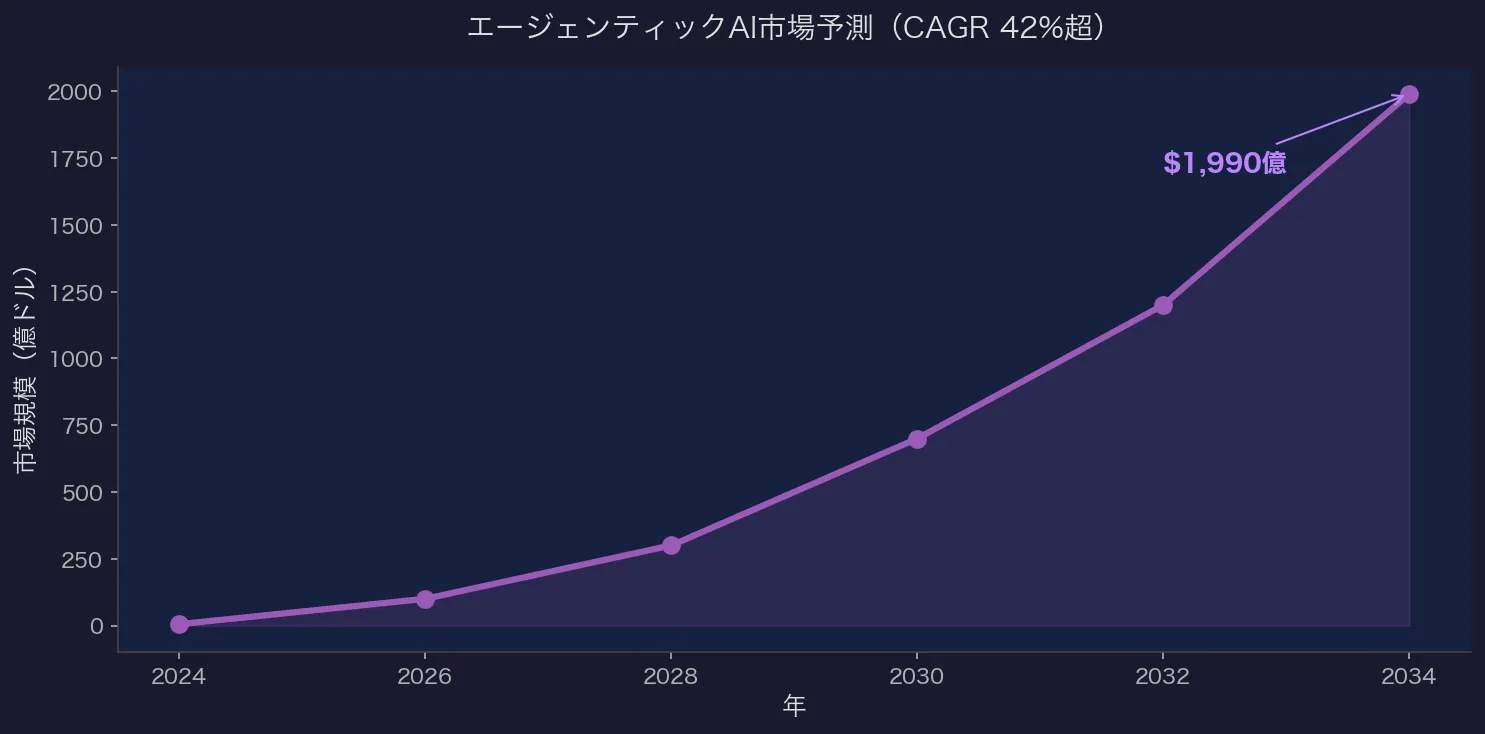
- 「エージェントの年」と謳われた2025年は、多くが「話題」に留まり実用化が追いつかなかった
今後の方向性(2026-2027)
短期(2026年)
- MCP + A2Aの組み合わせがエージェント間通信のデファクト標準に
- シングル/マルチの二者択一ではなく、タスク複雑度に応じた動的ルーティングが主流に
- Human-in-the-loopが必須。完全自律ではなく「人間監視付きエージェント」が現実的な導入形態
中期(2027年)
- 人間とエージェントが1:1で働く体制が大企業で現実に
- CRM/ERPは「自律ワークフローエンジン」の背後に後退
- AI流用スキルの需要が2年間で約7倍に成長
構造的トレンド
- LLMの能力が向上するにつれ、マルチエージェントの独自の価値提案は不明確になる
- ステップごとの精度問題(85%精度で10ステップ→成功率20%)を解決するガードレール技術が次のイノベーション領域
- コスト最適化が勝敗を分ける。Anthropicのマルチエージェントリサーチシステムはチャットの15倍のトークンを消費する
まとめ:いつ分けるべきか、いつ分けないべきか
データを横断的に見ると、かなり明確なパターンが浮かんでくる。
マルチエージェントが効く条件:
- タスクが真に並列分解可能(リサーチ、コードレビュー、多角的分析)
- 各エージェントに異なる専門知識が必要
- コンテキストが1エージェントに収まらない大規模プロジェクト
- シングルエージェントの精度が約45%を下回る難易度のタスク
シングルエージェント(+ツール)で十分な条件:
- タスクが逐次的で密結合(論理の一貫性が命)
- グローバルなコンテキスト共有が重要
- シンプルなタスク(オーバーヘッドのみ増加)
- コストやレイテンシに制約がある
最新の研究(arXiv 2505.18286)では、ハイブリッド設計(リクエストカスケーディング)で精度1.1-12%向上、コスト最大20%削減を実現できることが示されている。
そしてLLM自体の能力が向上するにつれて、マルチエージェントの優位性は縮小する傾向にある。「今は分けた方がいい」場面でも、半年後には1体で十分になっている可能性は十分ある。
Anthropicの公式メッセージが一番誠実だと思う——「シンプルに始めて、必要な時だけ分けろ」。